Overview
My recent on-call shift was quite the rollercoaster, but yielded valuable insights as usual. One particularly interesting incident was resolved by modifying our Quality of Service configuration for the impacted application pods to Burstable.
What does that mean? Well that’s what I’m hoping to address in this writeup as well as better grok it myself.
Quick Infra Overview
Our backend is divided into various K8s deployments, each with its own allocated resources:
- When students visit our platform, their interactions are handled by specific pods.
- Asynchronous job processing is handled in different pods.
- And so on…
Here’s a simplified schematic of the backend:
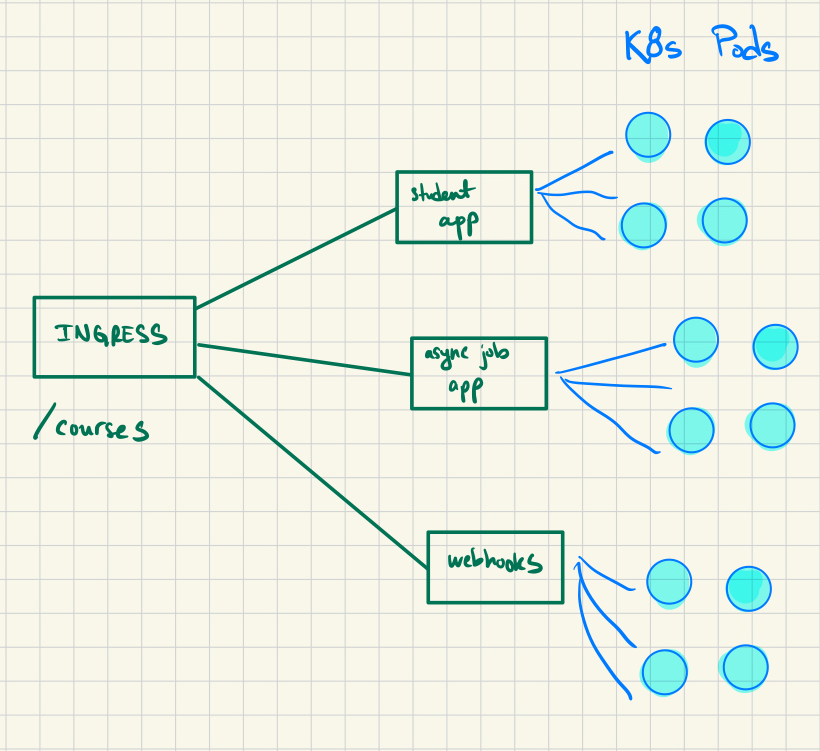
This modular design enables us to scale individual application components independently based on demand. For instance, if our student-facing application experiences a surge in traffic, additional pods can be dynamically provisioned (see horizontal pod autoscaling) to manage the increased load.
A Brief Look at HPA
Horizontal Pod Autoscaling (HPA) enables your application to adapt to various types of traffic load. You can configure a minimum and maximum number of replicas, within which your application can scale to in response to varying traffic load.
The decision of scaling direction is managed by the kube-control-manager.
The control manager uses metrics that are defined in your configuration to decide how the application should scale (add or remove pods).
However, sometimes adding more pods isn’t enough. Applications may be CPU or Memory bound and reaching these limits could result in pod crashing, regardless of the total pod count. This is where Quality of Service comes into play.
Quality of Service (QoS)
QoS is a way K8s is a mechanism for prioritizing pod eviction when a node experiences resource pressure (note that the pods ’live’ inside a Node). Additionally, the QoS is used to “beef-up” the pods as necessary before eviction.
There are 3 types of QoS, listed in order:
- Best Effort
- Burstable
- Guaranteed
Let’s bring in some, albeit forced 😂, analogies from fluid mechanics (because why not?!)
Best Effort
Pods are classified as Best Effort if there are no cpu/memory limits/requests defined. They can use resources up to the limits set at the node level.
These pods are the first to get evicted since they have no specific resource constraints and the assumption is that they are flexible to evict.
This QoS is suitable for low impact and time-insensitive workflows like log collection or periodic cleanup jobs.

Here you can see a structure (node) with no pod level limits (volume). Since there are no pod level limits, water can continue to flow until the max volume is reached. In K8s, this is equivalent to increasing node pressure, to the point where the pods get terminated.
Note that there are no cpu / memory limits defined in the K8s deployment file.
Burstable
Pods are classified as Burstable if there are cpu/memory requests defined. These pods can use cpu/memory up to the defined container limits or up to the Node limits if no container limits are defined.
This QoS allows for “elastic resource allocation” where the pod can expand and contract its resource usage based on load. These pods are next in the eviction line as they are constrained compared to “Best Effort” pods, but still more flexible than the “Guaranteed” pods.
Example of “Burstable” workflows include batch job processing and web app servers.
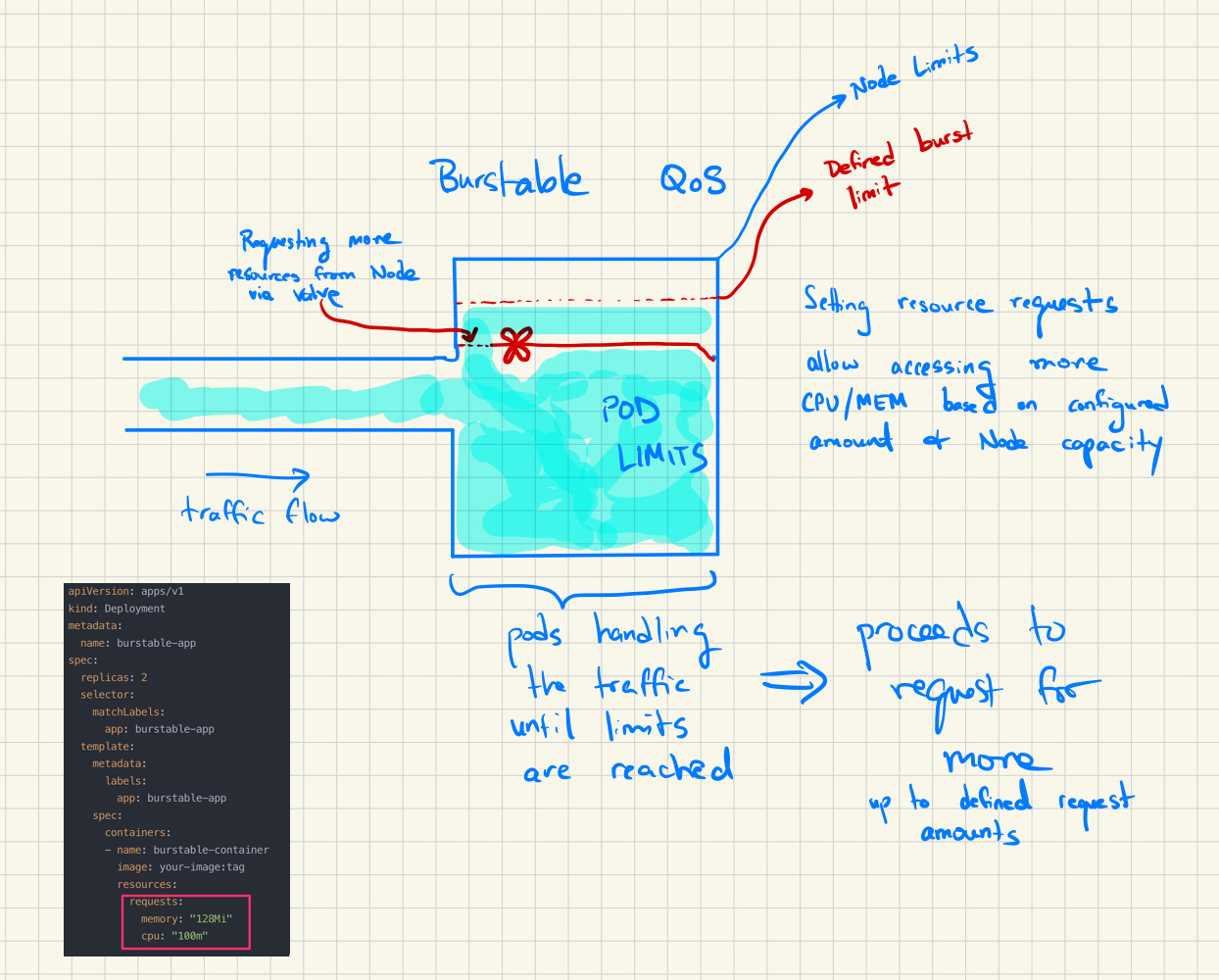
Here you can see the container with a “burst request / limit” portrayed by the valve. You can configure the resources request limits using this valve, which would allow more “volume to be taken up by the water”. Or in the case of the pods, more cpu/memory to be used.
Note that if you have requests defined without limits, the pods can burst up to use all of the node level resources. If you define limits, the pods will adhere to these specified thresholds.
Guaranteed
Pods are classified as Guaranteed if there are defined cpu/memory requests/limits. These pods can use NO MORE than the resources defined in the deployment file.
This QoS class defines a strict and consistent experience ideal for critical workloads. For example, a High Frequency Trading (HFT) platform may need workflows that are Guaranteed to ensure minimal latency and consistent operations even under peak load. If it was “Burstable” or “Best Effort” in nature, that would lead to inconsistent performance, higher latency, and higher risk.
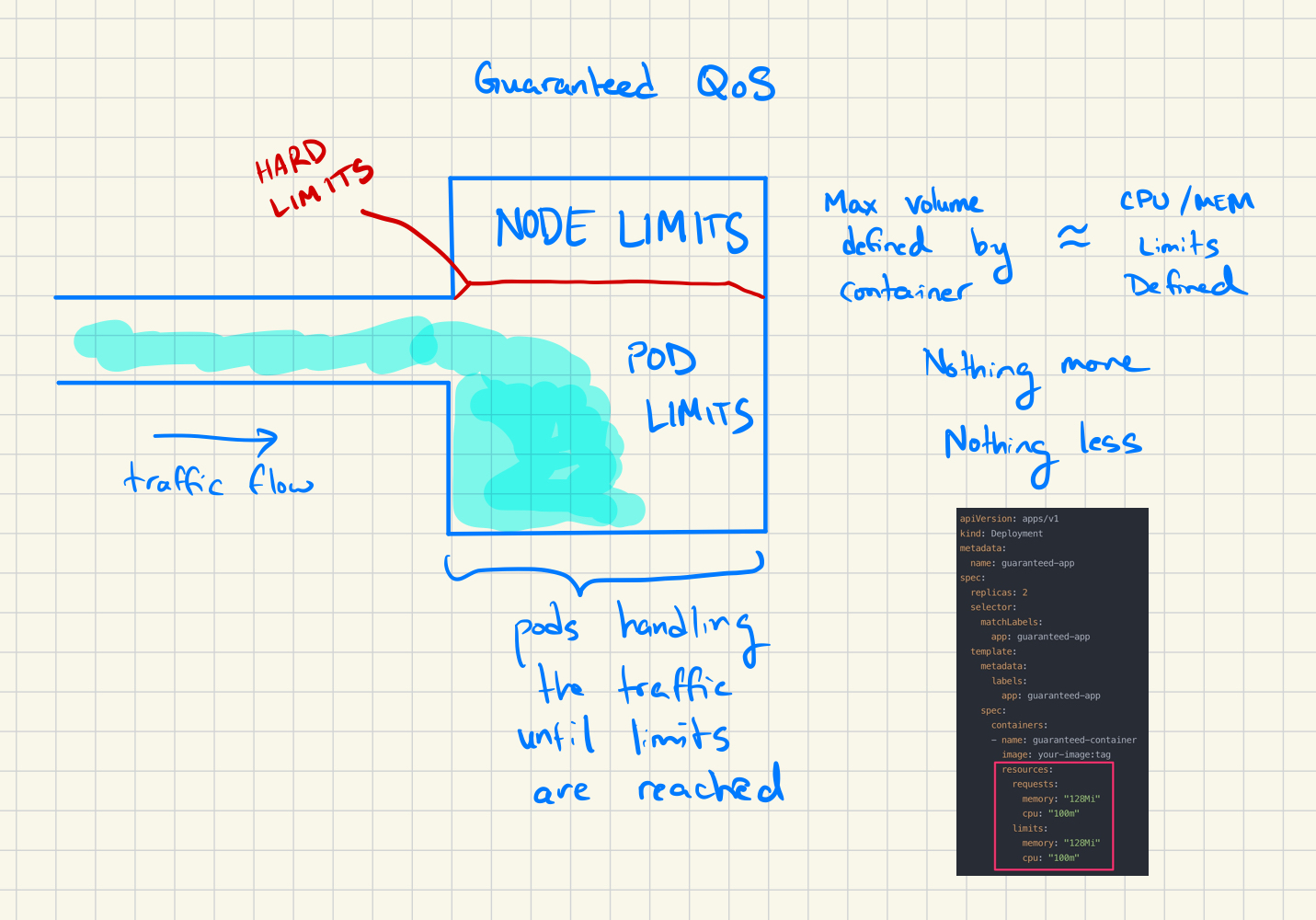
Here you can see the container with a hard limit on its volume. The pods will use up to the defined limits or be terminated otherwise. These pods are the last to be evicted given the constrained and critical nature of workflows that would be running under this QoS.
The Incident
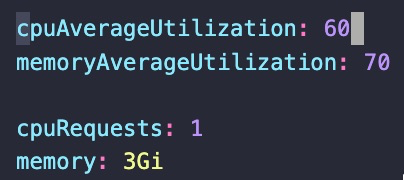
During the incident, our student-app pods were crashing due to reaching cpu limits. We had HPA in place, but it failed to scale up due to the metric we were using.
Our HPA uses cpuAverageUtilization and memoryAverageUtilization to decide if we should scale the pods up, but this calculation was skewed, preventing the HPA from adding more pods.
To resolve the issue, we updated the deployment config to have a Burstable QoS by setting the cpuRequests attribute. This allowed the application to access additional cpu up to the node limit.
Conclusion
It’s absolutely fascinating that we have can have such fine-grained control over the “adaptability” of our applications. There are definitely some gaps in my understanding here, but I’m hoping to plug them shut as I continue engaging with K8s.
P.S. During my descent into the QoS/HPA rabbit hole, I found this fantastic chart from Natan Yellin in this reddit thread that sums up the state of your pod based on the defined requests/limits.

P.S.S. The analogies are ROUGH. I wanted to box K8s concepts into fluid mechanics somehow and the result was the above haha.